Due anni fa, l'ex presidente Barack Obama ha annunciato il Iniziativa di medicina di precisione nel suo discorso sullo stato dell'Unione. L'iniziativa mirava a una "nuova era della medicina" in cui i trattamenti per la malattia potessero essere specificamente adattati al codice genetico di ciascun paziente. ![]()
Questo ha risuonato profondamente nella medicina del cancro. I pazienti possono già gestire il loro cancro con terapie che mirano ai geni specifici che sono alterati nel loro particolare tumore. Ad esempio, le donne con un tipo di cancro al seno causato dall'amplificazione del gene HER2 sono spesso trattate con una terapia chiamata herceptin. Poiché queste terapie mirate sono specifiche per le cellule tumorali, tendono ad avere meno effetti collaterali rispetto ai tradizionali trattamenti antitumorali con chemioterapia o radiazioni.
Tuttavia, tali trattamenti non sono disponibili per la maggior parte dei malati di cancro. In molti tumori, le specifiche alterazioni genetiche responsabili di un cancro rimangono sconosciute. Per creare trattamenti oncologici individualizzati, dobbiamo sapere di più sulle alterazioni genetiche funzionali.
Con i dati sulla genetica del cancro in rapida crescita, la matematica e le statistiche possono ora aiutare a sbloccare i modelli nascosti in questi dati per trovare i geni responsabili del cancro di un individuo. Con questa conoscenza, i medici possono selezionare trattamenti appropriati che bloccano l'azione di questi geni per personalizzare le terapie per i singoli pazienti. La mia ricerca mira a migliorare la medicina di precisione nel cancro - basandosi sugli stessi metodi che sono stati utilizzati per trovare modelli nelle classificazioni dei film di Netflix.
Setacciare i dati
Oggi c'è un accesso pubblico senza precedenti ai dati sulla genetica del cancro. Questi dati provengono da pazienti generosi che donano i loro campioni di tumore per la ricerca. Gli scienziati applicano quindi tecnologie di sequenziamento per misurare le mutazioni e l'attività in ciascuno dei geni 20,000 nel genoma umano.

Tutti questi dati sono un risultato diretto del Progetto Genoma Umano in 2003. Quel progetto ha determinato la sequenza per tutti i geni che costituiscono il DNA umano sano. Dal completamento di quel progetto, il costo del sequenziamento del genoma umano ha più che dimezzato ogni anno, superando la crescita della potenza di calcolo descritta in Legge di Moore. Questa riduzione dei costi consente alle ricerche di raccogliere dati genetici senza precedenti da pazienti oncologici.
La maggior parte degli studi scientifici sulla genetica del cancro eseguiti in tutto il mondo rilascia i loro dati in un database pubblico centralizzato fornito dalla National Library of Medicine degli Stati Uniti National Institutes of Health (NIH). Il NIH National Cancer Institute e il National Human Genome Research Institute hanno anche rilasciato liberamente dati genetici da più tumori 11,000 nei tipi di cancro 33 attraverso un progetto chiamato Il Cancro Genome Atlas.
Ogni funzione biologica - dall'estrazione di energia dal cibo alla guarigione di una ferita - deriva dall'attività in diverse combinazioni di geni. I tumori dirottano i geni che consentono alle persone di crescere fino all'età adulta e che proteggono il corpo dal sistema immunitario. I ricercatori ne citano il "Segni distintivi del cancro". Questa cosiddetta disregolazione genica consente a un tumore di crescere incontrollabilmente e di formare metastasi in organi distanti dal sito originale del tumore.
I ricercatori stanno attivamente utilizzando questi dati pubblici per trovare l'insieme di alterazioni genetiche responsabili di ciascun tipo di tumore. Ma questo problema non è così semplice è l'identificazione di un singolo gene disregolato in ciascun tumore. Centinaia, se non migliaia, dei geni 20,000 nel genoma umano sono disregolati nel cancro. Il gruppo di geni disregolati varia nel tumore di ciascun paziente, con serie più piccole di geni comunemente riutilizzati che abilitano ogni segno distintivo del cancro.
La medicina di precisione si basa sulla ricerca di gruppi più piccoli di geni disregolati che sono responsabili della funzione biologica nel tumore di ciascun paziente. Ma i geni possono avere molteplici funzioni biologiche in diversi contesti. Pertanto, i ricercatori devono scoprire una serie di geni "sovrapposti" che hanno funzioni comuni in una serie di pazienti oncologici.
Il collegamento dello stato genetico alla funzione richiede una matematica complessa e un'immensa potenza di calcolo. Questa conoscenza è essenziale per prevedere l'esito di terapie che bloccherebbero la funzione di questi geni. Quindi, come possiamo scoprire quelle caratteristiche sovrapposte per predire i risultati individuali per i pazienti?
Cosa Netflix può insegnarci
Fortunatamente per noi, questo problema è già stato risolto in informatica. La risposta è una classe di tecniche chiamata "fattorizzazione di matrice" - e probabilmente hai già interagito con queste tecniche nella tua vita di tutti i giorni.
Nel 2009, Netflix ha tenuto una sfida per personalizzare le classifiche dei film per ciascun utente Netflix. Su Netflix, ogni utente ha una serie distinta di valutazioni di diversi film. Mentre due utenti possono avere gusti simili nei film, possono variare selvaggiamente in determinati generi. Pertanto, non è possibile fare affidamento sul confronto tra valutazioni di utenti simili.
Invece, un algoritmo di fattorizzazione a matrice trova film con valutazioni simili tra un gruppo ristretto di utenti. Il gruppo di utenti varierà per ogni film. Il computer associa ciascun utente a un gruppo di film in misura diversa, in base ai loro gusti personali. Le relazioni tra gli utenti vengono definite "pattern". Questi pattern vengono appresi dai dati e possono trovare classificazioni comuni non previste dal solo genere di film, ad esempio gli utenti possono condividere una preferenza per un particolare regista o attore.
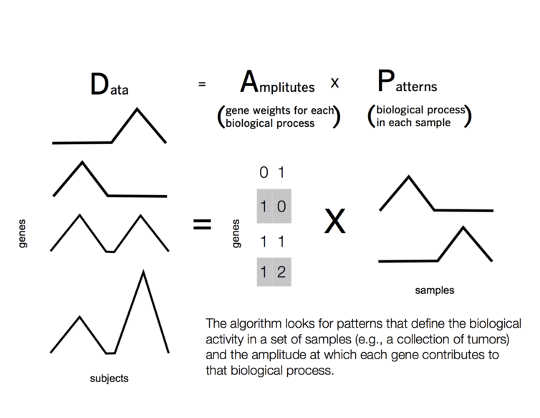 Genevieve Stein-O'Brien, CC BY
Genevieve Stein-O'Brien, CC BY
Lo stesso processo può funzionare nel cancro. In questo caso, le misurazioni della disregolazione genetica sono analoghe alle classificazioni dei film, ai generi cinematografici, alla funzione biologica e agli utenti dei tumori dei pazienti. Il computer cerca tra i tumori del paziente per trovare modelli di disregolazione genica che causano la funzione biologica maligna in ciascun tumore.
Dai film ai tumori
L'analogia tra le valutazioni dei film e la genetica del cancro si scompone nei dettagli. A meno che non siano minorenni, gli utenti di Netflix non sono limitati nei film che guardano. Ma i nostri corpi preferiscono invece minimizzare il numero di geni usati per ogni singola funzione. Esistono anche notevoli ridondanze tra i geni. Per proteggere una cellula, un gene può facilmente sostituirlo con un altro per svolgere una funzione comune. Le funzioni genetiche nel cancro sono ancora più complesse. I tumori sono anche molto complessi e in rapida evoluzione, a seconda delle interazioni casuali tra le cellule tumorali e l'organo sano adiacente.
Per tenere conto di queste complessità, abbiamo sviluppato un approccio di fattorizzazione della matrice chiamato Attività genica coordinata in insiemi di modelli - o in breve CoGAPS. Il nostro algoritmo spiega il minimalismo della biologia incorporando il minor numero possibile di geni nei modelli per ciascun tumore.
Diversi geni possono anche sostituirsi a vicenda, ognuno dei quali svolge una funzione simile in un contesto diverso. Per spiegare ciò, CoGAPS stima simultaneamente una statistica per i cosiddetti "pattern" della funzione genica. Questo ci consente di calcolare la probabilità che ciascun gene venga utilizzato in ogni funzione biologica in un tumore.
Ad esempio, molti pazienti prendono una terapia mirata chiamata cetuximab per prolungare la sopravvivenza nei tumori del colon-retto, del pancreas, del polmone e del cavo orale. Il nostro recente lavoro ha scoperto che questi modelli possono distinguere la funzione dei geni nelle cellule tumorali che rispondono all'agente terapeutico mirato cetuximab da quelli che non lo fanno.
Il futuro
Sfortunatamente, le terapie contro il cancro che colpiscono i geni di solito non possono curare la malattia di un paziente. Possono solo ritardare la progressione per alcuni anni. La maggior parte dei pazienti poi ricade, con tumori che non rispondono più al trattamento.
Il nostro recente lavoro trovato che i modelli che distinguono la funzione del gene nelle cellule che sono sensibili a cetuximab includono gli stessi geni che danno origine alla resistenza. Le immunoterapie emergenti sono promettenti e sembrano curare alcuni tumori. Eppure, troppo spesso, anche i pazienti con questi trattamenti ricadono. Nuovi dati che tracciano la genetica del cancro dopo il trattamento sono essenziali per determinare perché i pazienti non rispondono più.
Insieme a questi dati, la biologia del cancro richiede anche una nuova generazione di scienziati in grado di colmare la matematica e le statistiche per determinare i cambiamenti genetici che si verificano nel tempo nella resistenza ai farmaci. In altri campi della matematica, i programmi per computer sono in grado di prevedere i risultati a lungo termine. Questi modelli sono usati comunemente nella previsione del tempo e nelle strategie di investimento.
In questi campi e la mia precedente ricerca, abbiamo riscontrato che gli aggiornamenti dei modelli da serie di dati di grandi dimensioni, come i dati satellitari in caso di condizioni meteorologiche, migliorano le previsioni a lungo termine. Abbiamo visto tutti gli effetti di questi aggiornamenti, con le previsioni del tempo migliorando il più vicino che siamo a una tempesta.
Proprio come gli strumenti usati dall'informatica possono essere adattati sia alle raccomandazioni sui film che al cancro, la futura generazione di scienziati computazionali adotterà strumenti di previsione da una serie di campi per la medicina di precisione. In definitiva, con questi strumenti computazionali, speriamo di prevedere la risposta dei tumori alla terapia tanto comunemente quanto prevediamo il tempo e forse in modo più affidabile.
Circa l'autore
Elana Fertig, ricercatrice di biostatistica oncologica e bioinformatica, Johns Hopkins University
Questo articolo è stato pubblicato in origine The Conversation. Leggi il articolo originale.
libri correlati
at InnerSelf Market e Amazon